paper_read
本文最后更新于:2024年2月11日 晚上
文章阅读
NOTE:数学公式堂堂支持
NOTE: 调试数学公式恼羞成怒调整至notion中完成
paper_read
TODO list
nihao fdasfa
朗之万采样:从先验分布中随机采样一个初始样本,然后利用score逐渐将样本像数据分布的高概率密度区域靠近,同时为了生成结果的多样性,需要采用过程带有随机性。同时z服从正态分布,epsilon为每次移动的步长
Denoising Score Matching
固有:
rec && llm
Prompting Large Language Models for Recommender Systems: A Comprehensive Framework and Empirical Analysis
some finding
- Fine-tuning all parameters of LLMs for recommendation is more effective than parameter-efficient fine-tuning, but more training time is required
- Increasing the number of historical items to represent users brings insignificant gains for LLM
problem
- Existing literature has also found the position bias in LLM-based recommendations [32, 74, 133], and methods such as bootstrapping [32] and Bayesian probability framework [74] havebeen proposed to calibrate unstable results. However, the instability of LLMs is still an unresolved issue.
Adapting Large Language Models by Integrating Collaborative Semantics for Recommendation

idea
recinterpret + llara
motivation
integrate language and collaborative semantics for recommender systems Our approach can directly generate items from the entire item set for recommendation, without relying on candidate items.
method
- item indexing
- These item indices are learned based on the text embeddings of items encoded by LLMs, enabling the learned IDs to capture the intrinsic similarity among items
- 按照语义相关度,分割成树状的id
- finetune
- 多种推荐任务的文本描述finetune
LlamaRec: Two-Stage Recommendation using Large Language Models for Ranking

idea
升级版本tallrec,tallrec的候选list的延伸,通过logits+softmax的形式来进行重新排序,但是训练的方式同alpaca,但是用了pytorch-lighting的形式。
motivation 召回 排序
- 序列推荐召回list
- 设计了 verbalizer approach,用计算logits的方式作为打分依据,解决了推理时延问题
- 分词的方式是item逐一处理再进行拼接。
novelty
method
llm
Toolformer: Language Models Can Teach Themselves to Use Tools

idea
无监督的方式教会语言模型使用工具
motivation
相当于多遍扫描的过程,第一遍text插入在哪使用工具,第二遍通过替换工具的内容,通过loss函数的计算决定是否替换,然后用finetune的手段进行生成。
method
- 添加在哪里使用工具
- 调用工具,同时计算loss,设置阀值决定是否需要替换。
vision && LLM
VAE

CLIP

idea
our intuition is that CLIP models will need to learn to recognize a wide variety of visual concepts in images and associate them with their names
method
通过正负样本对进行训练,样本对通过编码器,然后同时对batch中多对样本进行点积处理,然后可以分出正负的样本对

diffusion
把picture作为视频的id,然后用文本进行生成,然后用生成的picture作为检索的策略?
- 文字LLM增大,encoder 成对资料更好,但是diffusion model扩大效果不好
- FID 评估指标 small is better
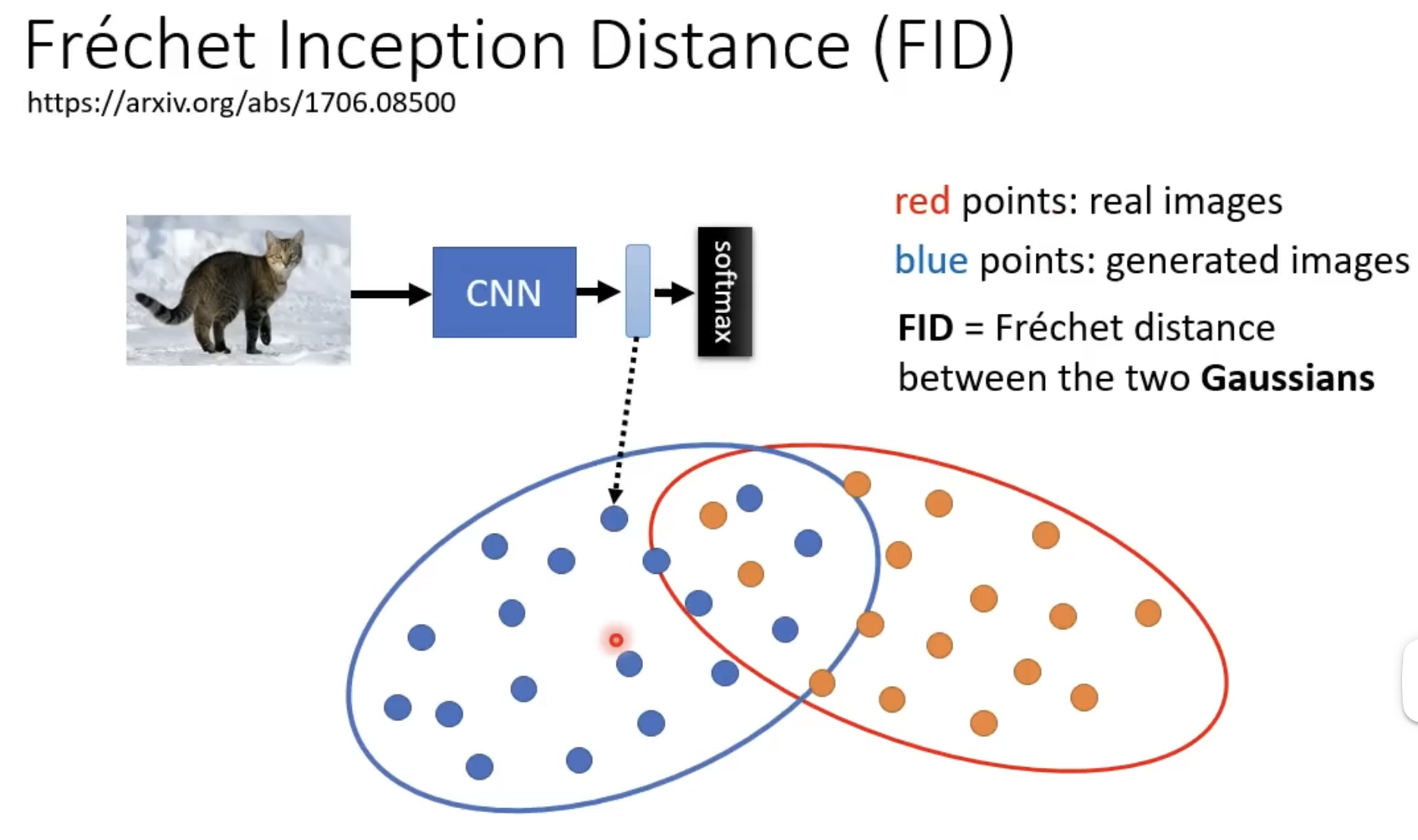
NLP-diffusion
通过token转换成embedding上面添加noise,再进行还原 [ ] to be done


stable diffusion
decode

i am blueheloo i am red
hel
ablity
application
- adaptive attendsion span
- class-free guidance
week
- transformer相关模型与blog
- 探究多模态推荐,主要学习diffusion模型,并复原了diffusion(DDPM)的代码。然后阅读的论文有clip(文本段和图片的对比学习),dalle2(unclip模型)。这两篇工作都强调了增大数据规模后,性能获得了大幅提升,(不确定diffusion+rec是否可行局限于rec数据集和CV数据集的差异,以及rec的数据量是离散的,之后计划阅读两者结合后的论文diffurec,以及打算阅读NLP上的diffusion应用和class-free guidance论文)